
ES 查询过程
ES查询
Coordinating 节点
每个节点都是协调节点。当客户端向一个节点发送查询请求时,这个节点就充当协调节点,协调节点需要处理本次请求:
解析请求参数,计算当前索引的分片;
广播查询请求到索引的各个分片,并行查询各分片数据;
合并所有分片的查询结果,返回到客户端。
两步查询
查询分两个阶段:
查询阶段协调节点将查询请求发送到当前索引的所有分片后:
各个分片根据 term 查询倒排索引取到 docId;
每个分片生成一个优先队列(根据 from size 确定),只包含 doc_id 和排序值;
所有分片将队列返回到协调节点。
取回阶段协调节点根据查询阶段查到的队列,汇总所有队列,截取 size 内容,向队列中 doc 所在的分片发起 Fetch 请求,取到 doc 的正排信息组装结果,最终返回给客户端。
深翻页请求深翻页请求为什么那么慢?在深翻页请求时:每一个分片都需要生成一个 from size 大小的队列,深翻页的 from 值一般都非常大,每个分片都需要计算资源来处理前 from 条数据,但是最终只取 size 大小的数据。CPU 和 memory 消耗都是随 ...

为什么需要 SearchEngine
为什么关系型数据库无法全文检索?慢关系型数据库通常以 B+ 树作为底层索引。一般我们在 MySQL 中模糊搜索这样用:
1select * from my_table where title like '%term%';
首先这个查询一定会触发全表扫描,即使 title 字段上建立了索引,like 语句中的 % 也会导致索引生效。
全表扫描有多慢?全表扫描本质上就是要把整张表的数据从磁盘中顺序读取出来,读取速度取决于存储介质的 I/O,因此耗时与数据量强相关,数据量越大,扫描时间越久。
相关性排序除了慢,传统数据库无法计算查询词与存储字段的相关性,数据库只保证查的出来,不保证查的相关性够强。
倒排索引
搜索引擎利用倒排索引解决上述问题。
倒排索引的本质上就是:term -> posting list 的映射。
如何构建倒排索引呢?分词 + 索引
分词搜索引擎中提供分词器 Analyzer,用于数据在写入倒排或者查询倒排时将内容切分成 term,成为倒排索引中的 key:term。
eg:有如下文本:小米手机, 为发烧而生,经过 Analyzer 处 ...

Lucene 创建索引
Lucene 创建索引SegmentLucene 将索引数据存储在 segment 中,segment 一旦写入磁盘,就不可再变:不可修改、不会删除。删除仅仅是逻辑删除,并不会物理删除;修改则是逻辑删除+写入新 segment。
写入链路
当有新索引需要写入,需要如下步骤:
写入索引缓冲区(index buffer),同时记录 translog,即事务日志,用于崩溃恢复;
Refresh:每隔 1s 将 buffer 中的 doc 刷新到 filesystem cache 中成为新的 segment,此时文档就可以被检索到了。 但还没有持久化到磁盘中。
间隔时间 refresh_interval 可以在 setting 中自定义,我们之前业务设定为 10s,意味着增量数据写入后大约 10s 可以被检索到,es 提供近实时搜索,属于业务可接受范围。
Flush:每当 30 分钟(默认) ,或者 filesystem cache 积累到一定程度、或者 translog 过大时,filesystem cache 会 flush 到磁盘中:
执行一次 refresh,清空 buffer; ...

分布式的 ES
分布式的 ES节点:一个物理或者虚拟的 ElasticSearch 进程,拥有 CPU、内存、磁盘等资源。只有 Data 节点可以持有分片;
分片:索引数据会被分成多个分片(都是主分片),副本分片是每个主分片的 copy,每个分片都是一个独立的 Lucene 索引。
ES 中一个索引(Index)逻辑上就是一个完整数据库,物理上会被分成多个分片(Shard),每个分片都是一个 Lucene 实例,Index 在创建时,分片数就确定了。
为什么要分片?
水平扩展:单个节点放不下的数据,可以分布在多个节点上;
并行处理请求:查询请求可以在多个分片中并行查询,最后合并,提高 I/O。
分片的分配创建索引时,索引一般有多个主分片,存储互不重复的数据子集。Master 节点需要计算这三个分片存到哪些 Data 节点上。
路由
前一篇描述了 Lucene 创建索引,因为在 es 中,每个分片都是一个 Lucene 节点,那么索引请求应该写入到哪个分片中呢?实际上会通过 doc_id 哈希取模得出分片 id:
1shard_num = hash(doc_id) % num_primary ...
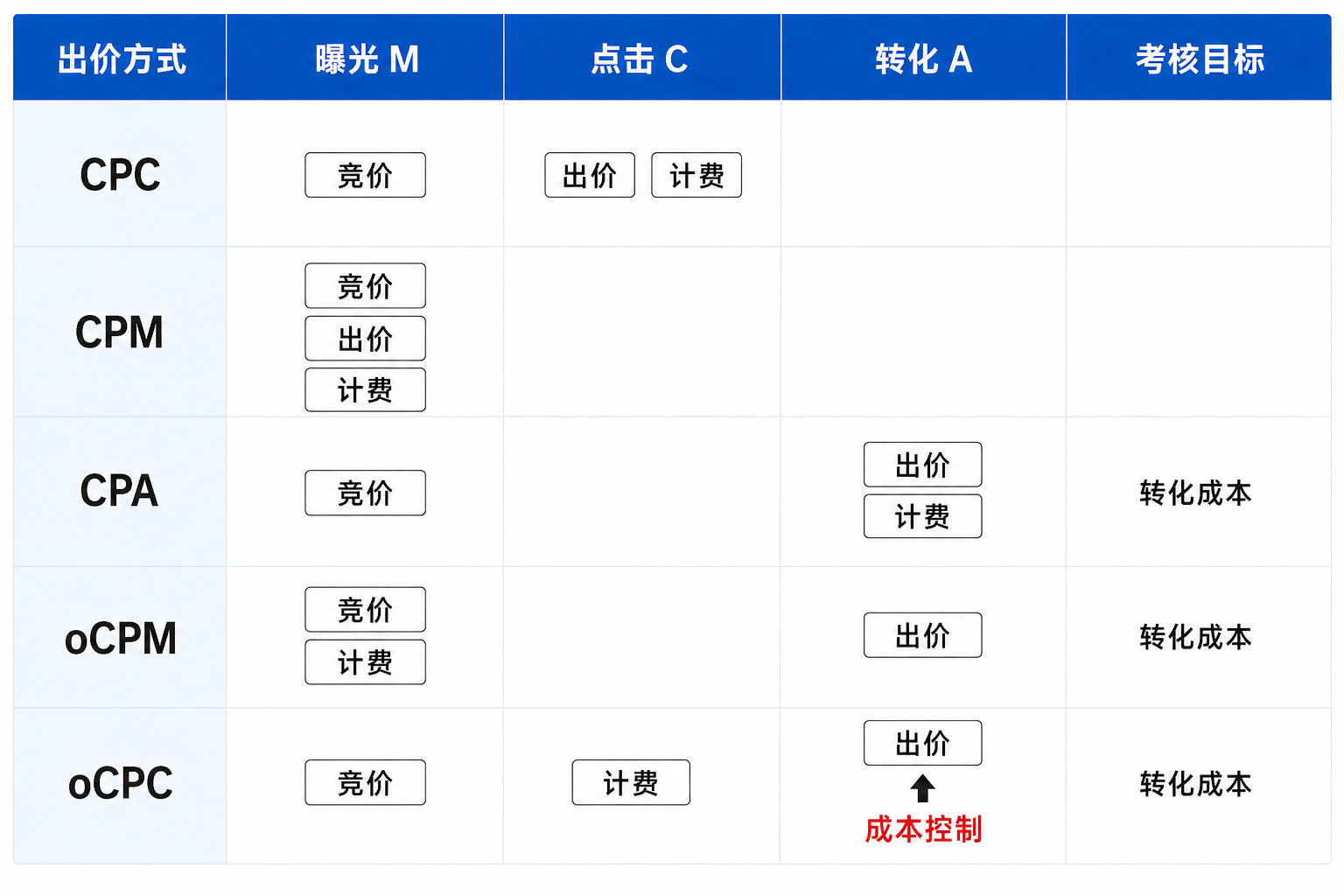
广告成本控制实践
出价机制与成本控制策略背景广告解决的是 媒体、广告主、平台之间的多方优化问题:
媒体在保证用户体验的前提下,实现商业化收入;
广告主的诉求是通过出价尽可能的优化营销目标;
广告平台则在满足以上两方需求的基础上实现广告生态的长期繁荣。
广告智能决策技术在这之中起到了关键性作用,基于以上需求,它需要解决这些问题:
为广告主设计并实现自动出价策略,提高广告投放效果;
为媒体设计拍卖机制来保证广告生态系统的长期繁荣。
简化工程架构12345678910111213141516171819202122232425262728293031323334353637用户请求 (e.g., 百度App信息流刷新) ↓ AFD (所有业务 app 服务端流量接入) ↓ NAR (分别请求所需内容下游) ↓ AS (预处理、adx 等) ↓ AS -> 请求触发 ↓ AS -> Proxy (请求召回) ↓ Proxy (下发召回请求) ...

广告检索系统
从 24 年开始接触广告系统,已经两年了。这里我将主要根据我个人工作的经验,结合业内优秀的系统案例,描述一下广告系统架构和广告相关知识点。
商业化广告业务商业化广告业务是一个广告主、平台、媒体三方平衡的商业化活动:
广告主是付钱投广告,希望拿到更多收益,提高 ROI;
媒体拥有流量入口,希望在保证用户体验的前提下,卖出广告位,实现商业化收入;
平台则是在需要平衡上述两者的需求,既要满足两者需求,也要保证平台生态的可持续。
商业化广告类型广告形式按广告形式来分主要是两大类:
搜索广告:用户搜索关键词时,出现在搜索结果页的广告;比如百度、Google 搜索后展示的广告;
展示广告(主要是原生广告):以多种媒体形式展现的广告,可能是视频、图片。原生广告就是与页面设计融为一体的广告,就像也页面里本来就该有的一样,不打断用户体验,信息流(Feed)广告就是典型的原生广告。
广告目标按照广告目标来分可以分成:
品牌广告:为品牌服务,提高曝光、注重触达、强化认知;多为 CPM、CPT 计价广告;
效果广告:注重效果,多为转化目标优化;通常是 CPC、CPA 计价广告。现在的在线商业化 ...

练级规划
再回首
小时候非常奢求能有一台电脑,主要是为了玩,大概是五年级,步入 3G 时代,我还在用爸妈的手机玩文字版 QQ 农场,那时在别人家看到他们打电脑游戏非常吸引我,因此想法设法去找有电脑的地方玩,初中后半段就开始去网吧玩。后来初中毕业,估摸着中考这么简单的问题难不倒我,然后以此为筹码和爸妈要求家里买了电脑,接入宽带,这可太开心了,这便是梦开始的地方。 虽然买来的电脑大部分情况下还是玩游戏,不过玩游戏这个需求也可以衍生出很多子需求,没钱啊,但是想玩游戏,想要比别人厉害,想要下载一些付费文档,怎么办?找盗版?开外挂?嗯是的。怎么找?别想了那时候没别的,只有 Baidu(虽然现在体验很烂但在十多年前还是要夸一夸的),各种论坛、贴吧,那可都是大神,一个破解论坛够我在其他人面前装逼了(这样我也成小孩假大神了,嘿嘿🤭),什么 office 不能用,小说下不下来?交给我!电脑坏了?我给你重装一下系统!这下我在中年老男人心里也成大神了!这是其一,另外靠着玩游戏,我在电脑前待了足够长的时间,怎么也对计算机略知一二吧,起码知道了 C 语言吧,知道了怎么装系统吧,这些额外收益让我受益匪浅。
如何学 ...

碎片
碎片🧩 && idea
C++的值类型
值类别
左值:通常来讲是可以放在赋值运算符左边的表达式,左值具有持久性,拥有确定的内存地址,可以使用取地址符获取;
右值:通常来说是放在赋值运算符右边的右操作数,它是一个临时值,无法取地址操作。
右值引用C++11 中引入了右值引用语义(&&),允许开发者对右值进行引用,从来实现移动语义和完美转发。
移动语义std::move 是 C++11 引入的标准库函数,将一个左值强制转换为右值,从而实现移动语义。通过std::move可以不进行复制实现将一个对象转移到另一个对象,提高了性能。但是std::move不移动任何东西,只是将传入的左值参数强制转化为右值引用
123456namespace std { template<typename T> constexpr remove_reference_t<T>&& move(T&& arg) noexcept { return static_cast<remove_reference_t<T>&& ...
Redis持久化
Redis 的持久化机制是说将 Redis 内存中的数据持久化到磁盘上,以防数据丢失。Redis 中的持久化机制一般有两种:
RDB(Redis DataBase):将 Redis 的内存中的数据快照周期性地写入磁盘,生成一个快照文件(.rdb),
AOF(Append Only File):AOF 持久化是将 Redis 的写操作以追加的形式写入日志文件。在 AOF 持久化模式下,所有的写命令都被追加到 AOF 日志文件中,以此来记录所有修改数据的操作,然后通过日志命令重放来还原数据。
{kind=link}