广告成本控制实践
出价机制与成本控制策略
背景
广告解决的是 媒体、广告主、平台之间的多方优化问题:
媒体在保证用户体验的前提下,实现商业化收入;
广告主的诉求是通过出价尽可能的优化营销目标;
广告平台则在满足以上两方需求的基础上实现广告生态的长期繁荣。
广告智能决策技术在这之中起到了关键性作用,基于以上需求,它需要解决这些问题:
- 为广告主设计并实现自动出价策略,提高广告投放效果;
- 为媒体设计拍卖机制来保证广告生态系统的长期繁荣。

简化工程架构
1 | 用户请求 (e.g., 百度App信息流刷新) |
机制
单目标拍卖机制
1. 一价拍卖
拍卖一个物品,最高出价者获胜,并支付其所报价格。
2. 二价拍卖
拍卖一个物品,最高出价者获胜,但支付次高出价者的报价(即第二高价)。
多目标拍卖机制
1. GSP(广义第二价格拍卖)
规则:
- 针对K个广告位的拍卖场景,所有竞拍者对每次点击进行出价
- 按出价从高到低排序,前K名依次获得广告位
- 支付规则:每个位置竞得者每次点击支付其下一位竞拍者的出价 + 微小值(如0.01元)
案例演示:
三个广告主A、B、C针对某个拍卖词出价:- A出价1元 → 获得第1位
- B出价0.8元 → 获得第2位
- C出价0.5元 → 获得第3位
点击A广告时:A支付B的出价0.8元 + 0.01元 = 0.81元
点击B广告时:B支付C的出价0.5元 + 0.01元 = 0.51元
2. PSA(基于位置的拍卖)
规则:
- 每个广告有质量分q(初始为CTR,后扩展至其他指标)
- 计算综合排序值:rankscore = bid × q
- 按rankscore从高到低分配广告位
- 支付规则:单位点击支付价 = 下一位竞拍者的rankscore / 自身质量分q
(此价格含义:保持当前竞得位置所需的最小出价)
与GSP核心区别:
排序依据从单纯出价变为出价与质量分的乘积(bid×q),引入广告质量与用户体验因素
3. VCG(Vickrey-Clarke-Groves)拍卖
分配规则:
选择使社会效用总和最大化的分配方案(如广告位组合)支付规则:
每个获胜者支付的费用 = 其参与导致其他竞拍者的价值损失总和
(精确公式:其他竞拍者在无该买家参与时的最大总价值 - 当前分配中其他竞拍者的实际总价值)优势:
- 激励兼容性:竞拍者如实报价是最优策略
- 效率最优:实现社会总价值最大化的资源配置
问题:
- 计算复杂性:商品/广告位数量增加时产生组合爆炸
示例计算:为3个广告位分配100条广告(每条含10种样式),需计算 (100 × 10)^3 = 10^9 种广告序列组合
- 计算复杂性:商品/广告位数量增加时产生组合爆炸
广告平台一般经历 GSP -> PSA -> VCG 三次迭代,但是 VCG 具有高度复杂性,所以这里对进入拍卖的广告要有严格的准入,大致为:粗排 200 条创意样式展开过滤最后优选一条,最多 50 条进入 ranker (平均 20 条),然后用这 20 条广告队列枚举一定量的 page排序,最后优选一个 page 完成拍卖。
自动出价和 oCPC
广告投放模式和自动出价系统的逐步演化:

当前主流平台的 信息流广告和搜索广告的投放模式是 oCPC。oCPC 是一个 Target-CPA 出价策略,客户直接表达目标转化成本 CPA,由平台自动出价来保证目标成本。
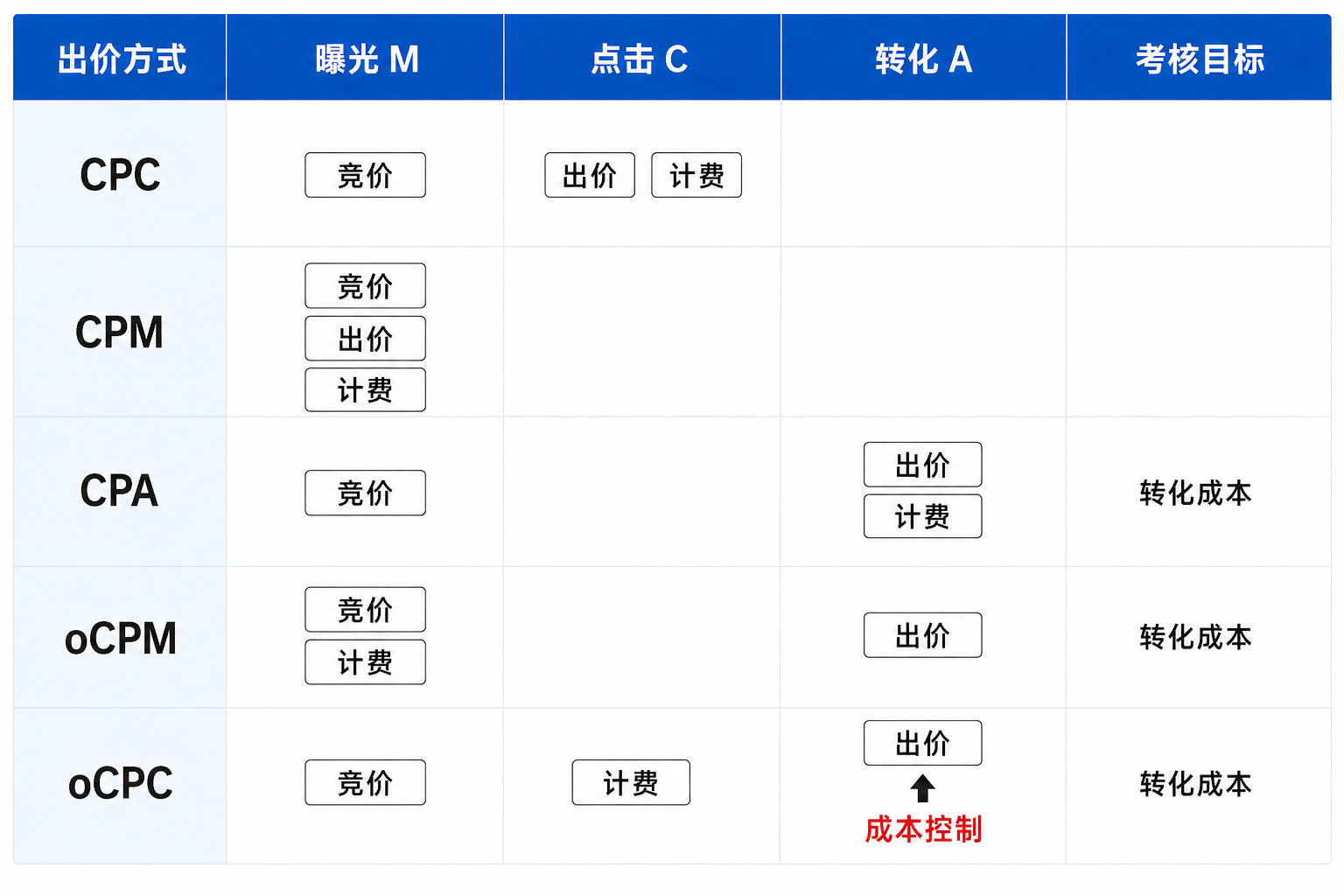
为什么oCPC 为什么会有成本问题?
| 计费方式 | 排序方式 | |
|---|---|---|
| CPM | bid(show) | bid(show) |
| CPC | bid(click) | ctr*bid(click) |
| oCPC | bid(click) | ctr * cvr * bid(conv) |
| CPA | bid(conv) | ctr * cvr * bid(conv) |
oCPC 广告在转化上出价,但是在点击计费:
oCPC 上计费点是 bid(click),出价点是 bid(conv) ,因此如果广告系统的出价不准确,会直接影响计费,最终影响客户投放成本。
成本控制
基础成本控制策略主要是三部分:
- 基础出价
- 反馈修正
- account 计费平滑
基础出价
ocpc 出价本质上是客户行为,因此最优出价要对于客户而已最优。
因此 oCPC 出价的核心目标是——在广告主给定的约束条件下,最大化转化数量。
核心思想
oCPC的目标是让系统代替广告主进行智能出价。广告主不再直接设定每次点击的出价(CPC),而是设定他们的核心业务目标(如:我想要更多转化)和限制条件(如:我每天最多花多少钱B,或者我希望每个转化平均成本不超过T)。系统则利用数据和算法,在每次竞价时动态决定一个最优的出价,以期在满足约束的前提下,实现广告主核心目标(转化量)的最大化。
建模
- 目标: 最大化广告主在一个周期内获得的转化数量。
- 假设:
- 未来所有流量信息可知
- 只考虑一个广告主
- 约束:
- 总花费限制: 总花费不要超过总预算。
- 转化效率限制: 竞价胜出的转化,平均成本不能超过CPA上限。单个转化不能太贵。
核心变量
核心约束
B (预算上限):广告主在一个预算周期内愿意花费的总金额上限。
T (平均转化成本上限, CPA上限):广告主可接受的平均每个转化所花费的成本上限。
其他变量
表示一个预算周期内,广告主可能参与的所有竞价机会总数量; 二元决策变量,表示用户第 `i` 次竞价结果,只能是 0 或 1; (点击率):**预估**的第 `i` 次竞价机会所对应的广告展现给用户后,用户**点击广告**的概率。 (转化率):**预估**的第 `i` 次竞价机会对应的用户**点击广告后,最终发生转化**(如下单、注册、留资等)的概率。 (单次点击成本):**预估**的第 `i` 次竞价机会**如果胜出()**,广告主需要为这次点击**实际支付**的费用。优化目标
: 这个乘积代表了赢得第 `i` 次展示机会后,**预期能带来的转化数量**; 只能是 0 或 1;
模型的目标是找到一组最优的 x_i 决策(哪些机会赢,哪些放弃),使得这组决策带来的总预期转化数量最大。直接对应广告主的核心诉求:获得尽可能多的转化。
约束条件
预算约束
: 赢得第 `i` 次展示机会后,**预期产生的广告消耗**。 是点击概率, 是点击成本,它们的乘积就是赢得这次展示后预期要花的钱(期望消耗)。
只能是 0 或 1;
:广告主在所有 `N` 次竞价机会中**赢得**的那些机会 () 所产生的**预期总消耗**;
转化成本约束
(总预期消耗) / (总预期转化量) <= T (平均转化成本 <= CPA上限 T),确保广告主获得的转化,其平均成本不超过设定的目标 T。
问题
假设一: 上述模型基于我们假设知道未来所有流量信息,实际上无法预知未来的 N、。
因此我们需要解决的问题是:
- 实时预估: 在每次竞价发生时,实时预估当前流量 (
i) 的 (或等效价值)。 - 反馈控制: 在预算周期内,根据已发生的花费和转化,以及剩余预算/时间,动态调整后续的出价策略(即决定后续的 ),以逼近全局最优。常用方法是 PID控制、强化学习等。
假设二: 是单一广告主:现实中一个广告平台同时服务海量广告主,竞价是相互影响的。一个广告主赢得竞价意味着其他广告主失去机会。对平台来说每个广告主都很重要。不过这个问题我们先不讨论。
求解复杂性: 0-1整数规划是NP-Hard问题。对于海量的 N (每天数十亿次竞价机会),精确求解这个模型在计算上是不可行的。
推导求解
此处省略推导求解过程。建议自行 GPT,没有头绪也可联系我。
最优出价策略
我们最终会得出
与 的关键关系:胜出时:
放弃时:
在广告竞价中,我们无法直接控制 (竞价结果),但可以控制出价 。在一般拍卖机制下(GSP), 通常小于或等于 。为了确保:
- 当最优解要求 (即竞价胜出)时,我们的出价 必须不低于 (否则赢不了)。
- 当最优解要求 (即竞价失败)时,我们的出价 必须不高于 (否则输不了)。
可以发现 这个阈值和 关系是一致的:
在GSP等二价拍卖中,该出价:
- 在需胜出时: ≥ (保证赢得曝光)
- 在需放弃时: ≤ (保证避免无效胜出)
因此我们就得出了 最优出价公式
线性出价公式
- 对于每一次竞价机会
i,系统应该根据预估的转化价值 ,乘以一个全局调控因子 来出价。 λ(预算乘子):反映预算约束的紧张程度。λ越大(预算越紧张),出价越低。ν(CPA乘子):反映CPA约束的紧张程度。ν越大(要求CPA越严格),出价越低。T(目标CPA):是广告主设定的目标成本,直接影响出价基准。
在许多广告场景中,广告主的日预算(B) 设置的相对充足(不会被快速消耗完),广告主的核心关注点是**转化成本效率(CPA ≤ T)**。
可以假设预算不限,此时 λ = 0:
出价由两部分组成:
- 成本:目标转化成本,确保对于转化率 的流量,出价与
T成正比。系统会竞争所有 不超过T的流量(因为 可以满足 )。 - 溢价:超出目标成本的空间,利用剩余 CPA 空间去竞争超成本流量。用于竞争那些转化价值高、但成本可能略高于
T的流量。ν是这个溢价程度的调控系数:ν大:表示CPA约束非常严格 ( 意味着约束起作用), 小,溢价项小,系统严格控制成本,只敢买很便宜或转化率很高的流量。成本容易达标,但可能错失优质流量,总转化量可能较低。ν小:表示CPA约束相对宽松 ( 意味着约束不太紧), 大,溢价项大,系统更激进,愿意为高转化率流量支付更高成本(即使单次转化成本可能超过T)。这有助于提升总转化量,但平均成本CPA可能升高。ν需要调整到使最终CPA接近T。
参数估计&&求解
定义一个因子 gap:
那么:
理想情况下,gap 应该等于实际赢得流量的总出价之和 / 实际赢得流量的总消耗之和。即:
如果 ,说明平均出价 > 平均成本,系统有“剩余购买力”去尝试竞争更贵(转化价值更高)的流量。
我们的目标是调整 gap,使得在按 出价后,最终达成的平均转化成本 接近目标 T。
- 迭代过程:
1. 初始化: 设定一个初始的gap值(例如gap = 1.0)。
2. 出价: 对于每个流量i,使用当前gap计算出价: 。
3. 竞价 & 统计: 参与竞价,记录胜出的流量、它们的 、实际扣费 和转化结果(用于计算总消耗、总转化)。
4. 计算新gap: 根据胜出流量的数据(参照公式 11),计算新的gap估计值。
5. 收敛判断: 检查gap的变化是否小于某个阈值,或者是否达到了最大迭代次数。如果未收敛,继续迭代。
本质上是通过 gap **在线估计参数 ν **。通过观察历史出价与实际成本的比例(gap),系统自适应地调整未来的出价激进程度(gap)。当 gap 收敛时,意味着系统找到了一个稳定的出价策略,使得出价成本比保持恒定,并在大概率下逼近目标 CPA = T。
说明
- 优化问题的直接解是 (是否胜出)。但我们需要的是 最优,因为竞价发生在决策之前。在 GSP 拍卖机制下,我们最优出价要保证:保证在最优解要求胜出()时,出价足够高以赢得该流量;在最优解要求失败()时,出价足够低以输掉该流量。
- 实际问题:
- 原始问题是一个整数规划问题。我们通过近似方法得到实用解。这个解是启发式的,不保证全局最优,但在工程实践中有效。
- 整个方法极度依赖对 , 的准确预估。公式中的 直接正比于 。如果预估不准:
- 高估 -> 出价过高 -> 赢得低质流量 -> CPA升高,转化量不达预期。
- 低估 -> 出价过低 -> 错失高质流量 -> 转化量减少。
- 迭代严重依赖历史数据,而未来流量是不可预测的。如果未来流量分布(用户特征、竞争环境)与历史数据差异很大,基于历史估计的
gap就会失效,导致成本控制 (CPA ≈ T) 或 转化量 不达预期。需要实时反馈机制(如PID控制器)来应对。
业内基础出价进展

一般广告平台都处在第二代,规划求解类:将出价建模为数学优化问题,基于历史数据预测流量,求解目标函数(如ROI最大化)。
阿里稳定上线第三第版本:现实环境的在线竞价环境是非常复杂且动态变化的,未来的流量集合也是难以精准预测的。需要统筹整个预算周期投放才能最大化效果。
凤巢、阿里目前再尝试将应用生成式模型应用到出价中,典型的是阿里 AIGB:https://zhuanlan.zhihu.com/p/619301816
反馈机制
上面的基础出价依赖精准预估流量的转化率,但实际上转化率预估模型存在一定偏差,并不能百分百决定接下来的 action。因此需要基础出价 + 反馈纠偏结合。
在广告出价系统中,现实偏差:roiq ≠ 真实价值(模型预估误差),竞争环境动态波动(比如竞争对手突然提价)。需要实时纠偏,将实际成本(如CPA)稳定在目标值附近。
PID 控制
比例控制: 基于当前窗口的实际成本与目标成本的瞬时偏差驱动调价
CPA突升20%,需要提高出价;但是系统作用有延迟,单纯比例控制会导致振荡(如出价提升后流量激增,CPA又低于目标)
积分控制: 消除累积偏差(如连续1小时CPA低于目标)
全天预算未耗尽但消耗过慢,积分项持续累积负误差,最终逐步提升出价。需要防止累积积分过大出现失控(积分项在出价中一般不生效)。
微分控制: 根据偏差变化趋势预测性抑制,避免预算提前花完。
实践
| 策略 | 门槛 | |
|---|---|---|
| 刹车 | 反馈系数刹车 | 一般是空耗 5 倍obid |
| 置信反馈 | 正溢出打压: 负溢出扶持: - ROI超目标时降出价 - ROI不足时提出价 按预算消耗/转化量分层修正 |
有一定 click 且有一定量转化 |
| 非置信反馈 | 贝塔分布预估原始 coe(微调) | 有一定量点击 |
离线强化学习
基于规则的PID控制策略存在的问题
依赖人工经验,数据利用率低,效果难保障:PID控制器需要手动调整参数(如Kp, Ki, Kd),依赖于经验。同时,PID只根据当前误差和近期历史进行调整,无法充分利用历史数据中的长期模式。
策略定制化程度高,迁移能力差:不同广告场景(如搜索、feed 、不同的目标甚至广告位)需要不同的PID参数。
特征构造
- 使用序列特征,直接采用过去n小时的数据序列 <转化置信度,溢出率,剩余时段流量分布> 作为特征。
业务目标: 溢出率
过程: 通过simulation日志和离线仿真环境,生成足量的
<x, ratio, score>样本。- 方法:
使用仿真日志中的广告候选集,通过模拟不同的出价,得到不同出价下的
charge、cv和score,从而构造样本。借鉴 DDPG(Deep Deterministic Policy Gradient) 的思路,搭建了两个网络:
- Score网络:拟合
<x, ratio>和score的映射关系。 - Ratio网络:将
ratio的枚举过程神经网络化,支持ratio为连续变量。
- Score网络:拟合
- 更新过程
- 方法:
步骤1:在
<x, ratio, score>样本集合上训练 Score网络。步骤2:固定 Score网络,更新 Ratio网络 的参数,目标是 **最大化
score**。
DT 序列建模
在 offline-RL 基础上,尝试用生成式模型解序列预测问题,引入 decision transformer,把RL 问题建模成序列预测问题,利用 GPT 的推理和学习能力,预测下一次序列产生。
传统 offline-RL 依赖 Markov 性和值函数估计,DT将RL 决策问题转化为条件序列生成:给定目标回报(Return-to-go)和历史状态动作,预测当前最优动作。
1. 输入序列构建
在广告出价场景中,一个决策轨迹由多个时间步组成,每个时间步包含三个元素:
Return-to-go (R_t): 从当前时刻到轨迹结束的累计回报(即剩余目标回报),由广告主设定的目标ROI计算得出。
State (s_t): 当前状态向量,包含预算状态、竞争环境、用户价值等特征。
Action (a_t): 当前时刻的出价动作(如出价系数)。
输入序列的严格顺序:
- 每个时间步内,元素顺序固定为:R → s → a。
2. 嵌入层(Embedding Layer)
每个输入元素通过 Embedding 转换为向量。

account 计费平滑
背景
有了基础出价+反馈纠偏能力,为什么还需要计费平滑?
在出价上:在转化比较少的场景,转化率模型预估难度非常大,系统通常会存在较大偏差。
反馈上:反馈准入门槛还是比较高的,并且转化数越少,数据越不置信。
最后,广告出价系统非常复杂,平台存在很多助攻、扶持、溢价策略,这部分策略直接修改 bid,不经过策略出价考虑。
如此下来客户成本很可能依然无法达成,account 计费调整更多的是作为兜底。
核心思想
通过高时效性的调整每一次 click 计费,使得高成本的时候少收钱,欠成本的时候多收钱,正负空余消费存入 account 池,理论上最终 account 余额保持在 0 是最优的。
基于规则
计费平滑模块的核心思想是利用系统的的波动鲁棒性去平滑计划的波动性,具体是给每个广告账户设定一个计费池,在该账户下的所有计划共享这个计费池,每个计费池设定阈值,在不超过这个偏差阈值的前提下,对账户下的计划每次计费进行“平滑”,即根据当前计划当天的实际 ROI 判定当前计划是该多收钱还是少收钱。

对于计划 i 在任意时间 t 时刻存在 3 个阶段,其中 Δt 为计划的转化延迟间隔:
1 | 0 ────── t-Δt ────── t ────── T |
假设为了在 t 时刻,使得 ROI 达成,计划 i 的计费应该为:
那么应该多收/少收多少钱呢?
- 项目 i 在时间 t−Δt 的 GMV、预估转化价值 (预估转化延迟)
- t - T 的预估转化价值,点击量 (可以参考历史数据)
- 客户设定目标 ROI
注意 price 和成本更新时效性非常高,预估可能不准确。
基于RL
放弃规则理论,将客户单日成本达成问题建模成序列优化问题,结合强化学习进行端到端优化。(未实践)
Reference
凤巢成本控制实践
「我在淘天做技术」迈步从头越 - 阿里妈妈广告智能决策技术的演进之路:https://xie.infoq.cn/article/f523e838b791b7542b3ac1da3
Decision Transformer: Reinforcement Learning via Sequence Modeling:https://arxiv.org/abs/2106.01345






{kind=link}